KernelEvolve: Automating AI Kernel Optimization at Meta's Scale
Introduction
Meta's global infrastructure processes billions of AI-powered requests every day, from personalized recommendations to generative AI assistants. Under the hood, a diverse fleet of hardware—NVIDIA GPUs, AMD GPUs, Meta's custom MTIA silicon, and CPUs—must execute complex machine learning models efficiently. The key to extracting peak performance from this heterogeneous mix lies in writing finely tuned software routines called kernels, which translate high-level model operations into chip-specific instructions.
Traditionally, kernel authoring has been a manual, labor-intensive process requiring deep expertise in both the model and the hardware. With each new chip generation and every novel model architecture, engineers must craft and optimize kernels from scratch. While vendor libraries cover standard operations like matrix multiplications and convolutions, production workloads often demand custom operators that fall outside these libraries. As the number of models and hardware types has exploded, hand-tuning by human experts has become unsustainable.
The Scale of the Problem
Meta operates a vast and growing array of hardware accelerators, each with its own programming model and performance characteristics. Optimizing kernels for this ecosystem means dealing with a combinatorial explosion: every model architecture times every hardware generation results in hundreds of unique optimization tasks. For a single production model like Andromeda—Meta's large-scale ads ranking model—the number of custom kernels runs into the dozens, and each one must be carefully profiled, tuned, and validated across multiple hardware platforms.
Human kernel engineers are a scarce resource. They typically spend weeks on each optimization cycle: analyzing performance bottlenecks, writing low-level code in languages like CUDA or HIP, debugging across different chip versions, and iterating based on profiling results. This manual process not only slows down deployment of new models but also limits the number of optimizations that can be explored. The need for an automated, scalable solution was clear.
Enter KernelEvolve
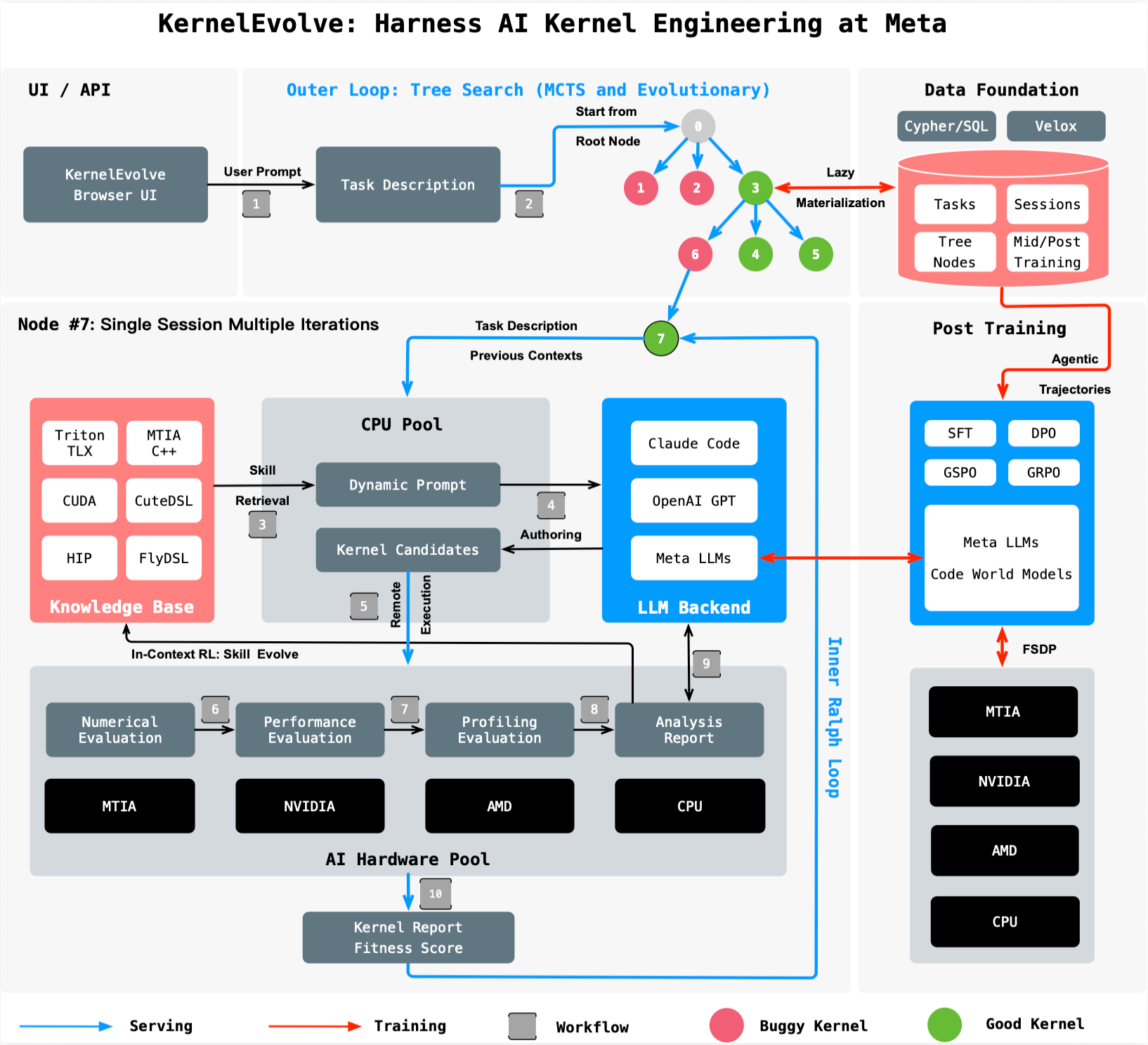
To address this challenge, Meta built KernelEvolve, an agentic kernel authoring system that is now a core capability of the company's Ranking Engineer Agent. KernelEvolve treats kernel optimization not as a static programming task but as a search problem—a fundamentally different approach that leverages large language models (LLMs) and automated evaluation loops to discover high-performance kernels far more efficiently than human experts.
How It Works: Optimization as a Search
At the heart of KernelEvolve is a closed-loop process. The system starts with an initial kernel implementation, often generated from a high-level description in domain-specific languages (DSLs) like Triton, Cute DSL, or FlyDSL. It then launches a job harness that compiles and runs the kernel on the target hardware, measuring key performance metrics such as latency, throughput, and memory bandwidth.
The profiling results are fed back to the LLM, which analyzes the bottlenecks and proposes modifications—maybe a different tiling strategy, a changed memory access pattern, or a more efficient use of on-chip registers. The harness evaluates each candidate, and the cycle repeats, driven by a continuous search over hundreds of alternatives. This automated, iterative refinement allows KernelEvolve to explore a far larger space of possible kernels than a human could, often discovering optimizations that even seasoned experts miss.
KernelEvolve is not limited to a single hardware platform or programming language. It works across NVIDIA GPUs (generating CUDA kernels), AMD GPUs (using HIP), Meta's custom MTIA chips (with MTIA C++), and CPUs. This flexibility is crucial for a heterogeneous infrastructure where the same model may run on different chips depending on availability and cost.
Measured Impact: Performance Gains at Scale
The results speak for themselves. For Meta's Andromeda ads model running on NVIDIA GPUs, KernelEvolve achieved a over 60% improvement in inference throughput compared to manually tuned kernels. On Meta's custom MTIA silicon, a training workload for another ads model saw over 25% throughput gains. These are not incremental tweaks—they are transformative improvements that translate directly to faster model serving, reduced latency, and lower operational costs.
Beyond raw performance, KernelEvolve dramatically compresses development timelines. What used to take weeks of painstaking human effort—profiling, optimizing, cross-hardware debugging—now happens in hours of automated search and evaluation. This frees up engineers to focus on higher-level model design and system architecture, rather than getting bogged down in low-level kernel tuning.
Broader Applicability Beyond Ads Ranking
While KernelEvolve was initially developed for ads ranking models, its design is general. The system's ability to optimize kernels across diverse hardware and programming models makes it applicable to any AI workload at Meta, from computer vision to natural language processing to generative AI. The underlying approach—treating kernel optimization as a search problem driven by LLM-based agents—is a paradigm that could be extended to other domains where low-level code performance is critical.
KernelEvolve is also a key enabler for Meta's custom silicon strategy. As the company deploys more MTIA chips, the ability to rapidly generate optimized kernels for these novel architectures is essential. Without an automated system like KernelEvolve, each new chip would require a large team of kernel engineers spending months writing and tuning code. Now, the agent does the heavy lifting in a fraction of the time.
Conclusion
KernelEvolve represents a significant step forward in the automation of AI infrastructure optimization. By reframing kernel authoring as a search problem and leveraging the power of LLMs to explore the optimization space, Meta has created a system that not only accelerates development but also delivers substantial performance improvements. As the company continues to scale its AI operations across an ever-diversifying hardware fleet, KernelEvolve will be an essential tool in ensuring that every model runs as efficiently as possible.
For those interested in the technical details, the full paper titled “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta” will be presented at the 53rd International Symposium on Computer Architecture (ISCA) 2026.
Related Articles
- Mozilla Upgrades Firefox's Free VPN with User-Selectable Server Locations
- Red Hat Unveils Fedora Hummingbird: A Rolling, Container-Native Linux Distribution
- Linux Standardizes 'Projects' Folder; Fedora 44 and Ubuntu 26.04 Land Amid Security Alerts
- Mozilla VPN Update: Now You Can Choose Your Server Location
- How to Get the Most Out of the LWN Weekly Edition
- Linux Kernel 7.1-rc2: Why This Prepatch Sparks AI Tooling Debate
- Fedora Asahi Remix 44 Arrives for Apple Silicon Macs
- Fedora Hummingbird: A Rolling, Container-Native OS for the Security-Conscious Developer